
Figure 1: A conceptual graph with nested contexts
Abstract. Every communication has syntax, semantics, and pragmatics. For computer communications, software designers have addressed syntax explicitly while leaving semantics and pragmatics implicit in their programs. But as software becomes more complex, the range of meanings (semantics) and purposes (pragmatics) grows without bounds. The failure to address purpose and meaning explicitly has led to different languages and GUIs for every conceivable purpose. By making meaning and purpose explicit, the designers can relate the bewildering variety of notations to a single semantic form: logic. Internal representations for logic can be any notation that is convenient for computer processing. External representations can be any form that people find convenient: graphics tailored for the applications, controlled versions of whatever natural languages the users speak, or any programming notations the developers happen to prefer. The unifying principle is the common logical form for both internal and external communications. To show how this principle can be implemented, this paper addresses the graphic and language interfaces for the Flexible Modular Framework (FMF) and their use in a semantically integrated development environment.
Presented at the International Conference on Conceptual Structures (ICCS) on 21 July 2004. Citation:
Sowa, John F. (2004) "Graphics and Languages for the Flexible Modular Framework," in K. E. Wolff, H. D. Pfeiffer, & H. S. Delugach, eds., (2004) Conceptual Structures at Work, LNAI 3127, Springer-Verlag, Berlin, pp. 31-51.
The semantics of any computer program, including any module of the FMF, can be expressed in logic. Internally, the logic may be represented in any suitable notation, of which the most general and flexible is conceptual graphs (CGs). The human interface relates the logic to one of three forms:
By itself, pure first-order logic (FOL) can be used for only one purpose: to assert propositions. But Peirce (1904) observed that propositions can be used for many purposes other than making assertions:
A proposition, as I have just intimated, is not to be understood as the lingual expression of a judgment. It is, on the contrary, that sign of which the judgment is one replica and the lingual expression another. But a judgment is distinctly more than the mere mental replica of a proposition. It not merely expresses the proposition, but it goes further and accepts it.... One and the same proposition may be affirmed, denied, judged, doubted, inwardly inquired into, put as a question, wished, asked for, effectively commanded, taught, or merely expressed, and does not thereby become a different proposition. (EP 2.311-312)In natural languages, the purpose of a proposition can be expressed in several ways: sometimes by syntax, as in questions and commands; sometimes by the context of a message, a conversation, or an extended discourse; and sometimes by a complex statement with multiple nested statements. As an example, the sentence Tom believes that Mary wants to marry a sailor, contains three clauses, whose nesting may be marked by brackets:
Tom believes that [Mary wants [to marry a sailor]].The outer clause asserts that Tom has a belief, which is expressed by the object of the verb believe. Tom's belief is that Mary wants a situation described by the nested infinitive, whose subject is the same person who wants the situation. Each clause states the purpose of the clause or clauses nested in it.
For logic to express the semantics and pragmatics of an English sentence, it must have an equivalent structure. The nested structure of the logic is shown explicitly in Figure 1, which is a conceptual graph for the sentence about Tom's belief. The large boxes, which contain nested CGs, are called contexts. The labels on those boxes indicate how the contexts are interpreted: what Tom believes is a proposition stated by the CG nested in the context of type Proposition; what Mary wants is a situation described by the proposition stated by the CG nested in the context of type Situation. The relations of type (Expr) show that Tom and Mary are the experiencers of states of believing or wanting, and the relations of type (Thme) link those states to the contexts that express their themes. The two relations attached to [Person: Mary] indicate that Mary is the experiencer of [Want] in one context and the agent (Agnt) of [Marry] in another context.
Figure 1: A conceptual graph with nested contexts
When a CG is in the outermost context or when it is nested in a context of type Proposition, it states a proposition. When a CG is nested in a context of type Situation, the stated proposition describes the situation. When a context is translated to predicate calculus, the result depends on the type of context. In the following translation, the first line represents the subgraph outside the nested contexts, the second line represents the subgraph for Tom's belief, and the third line represents the subgraph for Mary's desire:
(∃a:Person)(∃b:Believe)(name(a,'Tom') ∧ expr(a,b) ∧ thme(b,
(∃c:Want)(∃d:Situation)(person(Mary) ∧ expr(c,Mary)
∧ thme(c,d) ∧ dscr(d,
(∃e:Marry)(∃f:Sailor)(agnt(e,Mary) ∧ thme(e,f))))))
For the subgraph nested inside the context of type Situation,
the description predicate dscr relates
the situation d to the proposition expressed by the subgraph.
Each context of a CG or its translation to predicate calculus is limited in expressive power to pure first-order logic, but a proposition expressed in any context can make a metalevel assertion about the purpose or use of any nested proposition. To represent the model-theoretic semantics for a hierarchy of nested metalevels, Sowa (2003) developed nested graph models (NGMs), which support a first-order style of model theory for each level and a first-order style of interconnections between levels. A hierarchy of metalevels with the NGM semantics can express the equivalent of a wide range of modal, temporal, and intentional logics. Equivalent hierarchies can also be expressed in controlled NLs by translating the syntactic structure of a complex sentence or discourse to the contexts of CGs or their equivalents in predicate calculus.
During the twentieth century, Peirce's observations about the various uses and purposes of propositions were independently rediscovered and elaborated by various philosophers and linguists. Each version focused on a different aspect of language use:
Giving orders, and obeying them; describing the appearance of an object, or giving its measurements; constructing an object from a description (a drawing); reporting an event; speculating about an event; forming and testing a hypothesis; presenting the results of an experiment in tables and diagrams; making up a story, and reading it; play acting; singing catches; guessing riddles; making a joke, telling it; solving a problem in practical arithmetic; translating from one language into another; asking, thanking, cursing, greeting, praying.
In the FMF, any community of interacting agents can be viewed as the participants in a language game that motivates the interactions, both logical and physical, and the associated speech acts. For communications among the agents, McCarthy (1989) proposed a language called Elephant, which uses logic as the metalanguage for stating speech acts and as the object language for stating the propositional contents. The FMF incorporates a version of Elephant, in which the logic may be expressed in any suitable notation: controlled natural languages for communication with humans and any machine-oriented notation that may be appropriate for software agents. Graphics may also be used to supplement the logic for presenting relationships that are easier to show than to describe.
Section 2 of this paper surveys various notations for logic and their expression in controlled NLs. Section 3 presents a more detailed example of CLCE and its use in describing a three-dimensional structure and its mapping to and from a relational database. Section 4 discusses tools and methods for integrating language and graphics. Section 5 discusses the use of logic and controlled NLs in a semantically integrated development environment. The concluding Section 6 shows how techniques for processing unrestricted natural languages can be used to detect and correct errors in controlled NLs and to help authors observe the restrictions.
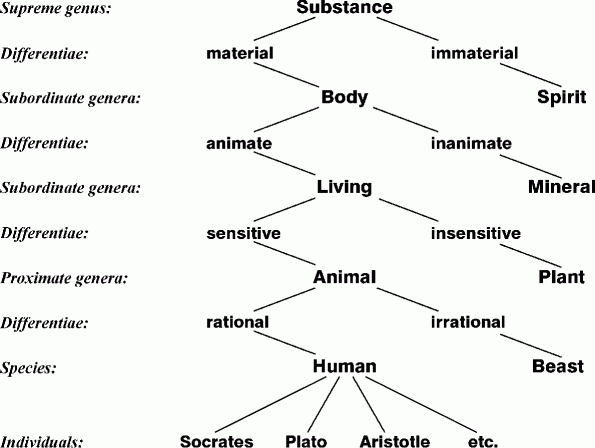
Figure 2: Tree of Porphyry by Peter of Spain (1239)
For his syllogisms, the first version of formal logic, Aristotle defined a highly stylized form of Greek, which became the world's first controlled natural language. In describing the relationships between Aristotle's logic and ontology, the philosopher Porphyry drew the first known hierarchy of categories. The version shown in Figure 2 was used in the middle ages to illustrate categories and their relationships to the syllogistic patterns, which were expressed in controlled Latin. Figure 3 shows the four types of propositions used in syllogisms and the sentence patterns that express them.
| Type | Name | Pattern |
|---|---|---|
| A | Universal affirmative | Every body is a material substance. |
| I | Particular affirmative | Some body is animate. |
| E | Universal negative | No mineral is animate. |
| O | Particular negative | Some body is not animate. |
Figure 3: The four sentence patterns used in syllogisms
The sentence of type A indicates that a category such as Body is distinguished by the differentia material from its genus Substance. Sentences of types I, E, or O state implications or constraints on the hierarchy. The differentiae are the features or properties that distinguish a category from its supertypes, subtypes, or siblings. The hierarchy of types and subtypes of categories can be defined with the verb is. Differentiae and other properties can be expressed with any verb phrase, as in the following sentences:
Every human has two parents. Every animal X can move some part of the body of X. Every cat eats some food that is derived from an animal.
Although these sentence patterns may look like English, they are limited to a highly constrained syntax and semantics: each sentence has a fixed quantifier pattern, at most one negation, and a predicate that is true or false of the individuals indicated by the subject. This subset of English is sufficient to support the description logics, such as the Web Ontology Language (OWL), whose logical foundation is based on Aristotle's syllogisms. Every category or class of entities can be defined by one or more sentences of type A. Inheritance of properties from a type to an individual is determined by syllogisms of the following form:
Every human has two parents. Socrates is a human. Therefore, Socrates has two parents.Other patterns determine inheritance from a supertype to a subtype, and syllogisms with negations (type E or O sentences) can check for inconsistencies. These sentence patterns can be mapped to specifications in many versions of logic. Following is the OWL representation for "Every human has two parents":
<owl:Class rdf:about="#Human">
<rdfs:subClassOf><owl:Restriction>
<owl:cardinality rdf:datatype="&xsd;nonNegativeInteger">2
</owl:cardinality>
<owl:onProperty rdf:resource="#Parent"/>
</owl:Restriction></rdfs:subClassOf></owl:Class>
Another subset of logic is expressed by the Entity-Relationship diagrams, which are widely used in database design and software specifications. Figure 4 shows an E-R diagram that relates four entity types: Student, Department, Course, and Section. The entities are represented by boxes, and the relations by diamonds. Each path of box-diamond-box can be expressed by a pair of controlled English sentences, one for each direction of reading the path. The lower right corner of Figure 4, for example, may be expressed by the following two sentences:
Every section presents exactly one course. Every course is taught in one or more sections.As this example shows, the readings for the two directions may use different words, which need not occur inside the diamond node. However, the mapping from those words to the name of the relation must be specified by declaration statements for the chosen vocabulary. Those words are used in variants of type A sentences in which the second quantifier specifies a number or a range of numbers, such as exactly one or at least 3 and no more than 7.

Figure 4: E-R diagram for students, departments, courses, and sections
The Unified Modeling Language (UML) includes type hierarchies similar to Figure 2, E-R diagrams similar to Figure 3, and several other kinds of diagrams used for software specifications. All UML diagrams can be expressed by controlled NL sentences that map to some subset of first-order logic (FOL). As an example, the UML activity diagrams, which are variants of Petri nets, can be expressed by the Horn-clause subset of FOL. Each activity or Petri-net transition can be specified by an if-then statement in which the if-part is a conjunction of preconditions, and the then-part specifies the activity and its postconditions:
If a copy of a book is checked out, the copy is returned, and a staff-member is available, then the staff-member checks in the copy, the copy is available, and the staff-member is available.The three clauses of the if-part specify three preconditions. The clause immediately after the word then includes a verb that names the activity (check-in) and two noun phrases that identify its participants (the staff member and the copy). The final two clauses are the postconditions. Further details about the check-in activity could be specified by another activity diagram, Petri net, or paragraph of controlled English sentences. Sentences of this form are translated to executable form by the ACE system (Fuchs et al. 1999, Schwitter 1998). More recently, Fuchs, Schwitter, and others have extended the English syntax they support and the expressive power of the logic they generate.
All the controlled English examples in this paper can be expressed in Common Logic Controlled English (Sowa 2004). The CLCE translator maps CLCE to an internal representation in conceptual graphs, which it can then map to several notations for first-order logic: predicate calculus, Conceptual Graph Interchange Format (CGIF), and Knowledge Interchange Format (KIF). Following is the CGIF representation of the previous if-then sentence:
[If: (Copy [Copy: *x] [Book]) (CheckedOut ?x)
(Returned ?x) (Available [StaffMember: *z])
[Then: (CheckIn ?z ?x) (Available ?x) (Available ?z)] ]
And following is the corresponding KIF statement:
(forall ((?x Copy)(?y Book)(?z StaffMember))
(=> (Copy ?x ?y)(CheckedOut ?x)(Returned ?x)(Available ?y)
(and (Checkin ?z ?x)(Available ?x)(Available ?y))))
CLCE, KIF, and CGIF can represent the full range of operators and quantifiers of first-order logic. By using FOL as the metalanguage, CLCE, KIF, and CGIF can be used to define and express extensions to FOL that can support versions of modal logic and higher-order logic. Gerbé and his colleagues (1998, 2000) used conceptual graphs as a metalanguage for software specifications, which are automatically translated to versions of controlled English and controlled French. Martin (2002, 2003) implemented a translator that maps controlled English to several notations, including UML, RDF, OWL, CGIF, and KIF.

Figure 5: Two structures represented in a relational database
For this example, CLCE nouns can be mapped to selections from the database tables, and CLCE names can be mapped to data in the tables themselves. In the following declaration, the syntax of each word is specified by its part of speech (e.g., noun or functional noun) and by a pattern for words that require more than one argument (e.g., x1 shape of x2). The semantics of each word is specified by the name of a predicate or relation that represents it in FOL and by an SQL query that maps the FOL relations to some selection from the database.
Declare object as noun
from SQL("SELECT ID FROM OBJECTS"),
shape as functional noun (x1 shape of x2)
from SQL("SELECT SHAPE, ID FROM OBJECTS"),
color as functional noun (x1 color of x2)
from SQL("SELECT COLOR, ID FROM OBJECTS"),
supporter as noun (x1 supporter of x2)
with relation(support)
from SQL("SELECT * FROM SUPPORTS"),
supportee as noun (x2 supportee of x1)
with relation(support);
The first line of the declaration states that the CLCE word
object is a noun. Its default relation object
is monadic when no variables are stated in the pattern, and
the data that defines the relation is obtained from the SQL statement
enclosed in parentheses. That statement extracts the ID column
from the table named OBJECTS to define object(x).
The next four lines define the words shape
and color as functional nouns represented by dyadic relations,
each of which corresponds to two columns of the OBJECTS table.
The fifth line defines supporter as a relational noun,
whose relation named support contains the complete data
from the database table named SUPPORTS.
The last line defines supportee as a relational noun with
the same support relation, but with the arguments reversed.
The next declaration specifies all the entries in the database tables as CLCE names. In FOL, it is represented an existential quantifier for each name. Unlike variables, whose scope is limited to a single sentence or less, names have the entire text as scope.
Declare pyramid, block as name of shape,
red, green, yellow, blue, orange
as name of color,
A, B, C, D, E, F, G, H
as name of object.
After the nouns and names have been declared, the top structure shown in Figure 5 can be described by the following CLCE sentences. To illustrate the various stylistic options in CLCE, each of the five objects is described with different stylistic conventions.
The shape of A is pyramid; the color of A is red; A is a supporter of D. Pyramid is the shape of B; green is the color of B; a supporter of D is B. C has pyramid as shape; C has yellow as color; D is a supportee of C. D is an object that has block as shape; the object D has blue as color; a supporter of the supportee E is the supporter D. The shape of E is pyramid, and the color of E is orange.Different stylistic choices in CLCE may lead to different representations in FOL, but they are all logically equivalent. Much of the variation is reduced or eliminated in the translation from CLCE to FOL, and the FOL rules of inference can be used to determine the equivalence of any remaining variability. The CLCE translator would map the above sentences to ground-level assertions in any notation for FOL, and the tools that map to SQL would generate database updates.
The declaration statements above defined nouns and names that were sufficient to describe the two structures of blocks and pyramids; no verbs, adjectives, or prepositions are needed. However, a logically equivalent description could be stated by representing the database table Supports by the English verb support. The following declaration defines that verb with two patterns for expressing relations in either active voice or passive voice:
Declare support as verb
(instrument supports theme)
(theme is supported by instrument)
from SQL("SELECT * FROM SUPPORTS");
In the active pattern, the role instrument (Inst),
which comes before the verb, occurs in subject position,
and the role theme (Thme), which comes after the verb,
occurs in object position. In the passive pattern,
those two positions are reversed: the theme is the subject,
and the instrument is the object of the preposition by.
Those two roles are used in the role representation for verbs;
the presence of two roles in the declaration indicates that
the relation is dyadic.
The SQL statement indicates the source of the data; it may be omitted
if the relation support(x1,x2)
has already been specified by an earlier declaration.
With the verb supports many propositions, such as A supports B, can be stated more simply than with the nouns supporter and supportee. But for some propositions, the nouns can be used to simplify the statements:
For every object x that has orange as color, every supporter of x has block as shape. For every object x that has orange as color, every object that supports x has block as shape.Both of these CLCE sentences are translated to the same form in FOL.
Instead of using the word block as the name of a shape and orange as the name of a color, it may be more convenient to declare block as a special kind of object and to declare orange as an adjective. Those declarations would require more complex SQL statements to define the monadic predicates that correspond to the noun and the adjective:
Declare block as noun
from SQL("SELECT ID FROM OBJECTS
WHERE SHAPE='block'"),
orange as adjective
from SQL("SELECT ID FROM OBJECTS
WHERE COLOR='orange'").
With these declarations, the previous statements become
For every orange object x, every supporter of x is a block. For every orange object x, every object that supports x is a block.The current version of CLCE prohibits universally quantified noun phrases from being used as the object of a preposition. Without that restriction, the previous statement could be simplified further:
Every supporter of every orange object is a block.These statements could be derived by data mining programs, which search for generalizations found in the database, or they could be stated as constraints enforced by restrictions on permissible updates.
These examples show how CLCE can be related to a relational database by means of the keyword SQL in the declarations. The SQL syntax is not recognized by the CLCE translator, which merely passes the quoted SQL statement to an interface program that links CLCE to the database. Other keywords, such as UML or URI, could be used to link CLCE to data from UML definitions or from resources located anywhere on the Internet.
Translating informal graphics to logic is as difficult as translating unrestricted natural language to logic, but it is much easier to translate logic or a controlled NL to graphics. Cyre and his students (1994, 1997, 2001) have developed tools and techniques for analyzing both the language and the diagrams of patent applications and translating them (semiautomatically) to conceptual graphs. They also designed a scripting language for automatically translating CGs to circuit diagrams, block diagrams, and other graphic depictions. Their tools can also translate CGs to VHDL, a hardware design language used to specify very high-speed integrated circuits (VHSIC). To add comments to the VHDL specifications, they developed the Controlled English Commenter (CEC) for helping human designers write controlled English and stay within its restrictions. After writing a few comments and being corrected and guided by the CEC, the users quickly learned to adapt to the CE restrictions and stay within its limited syntax and vocabulary.
For Cyre's constructions, one kind of graph is translated to another: some concepts of a CG map to icons; other concepts specify modifiers that may change the size, shape, color, or other properties of the icons; and relations specify various connections among the icons and their properties. Three-dimensional scenes allow a greater range of variability, which require a considerable amount of background knowledge for determining how objects are related. The WordsEye system (Coyne & Sprout 2001) analyzes descriptions stated in controlled English, translates them to a logical form, constructs a 3D scene containing the objects mentioned, and maps the scene to a 2D display. Following is the description from which WordsEye generated a scene and displayed it:
John uses the crossbow. He rides the horse by the store. The store is under the large willow. The small allosaurus is in front of the horse. The dinosaur faces John. A gigantic teacup is in front of the store. The gigantic mushroom is in the teacup. The castle is to the right of the store.For each object mentioned, WordsEye has a default representation. Adjectives such as small, large, and gigantic modify the representations, and verbs such as uses and rides relate the objects and adapt their representations appropriately. As the authors admit, WordsEye will not replace other methods for creating scenes, but even in its current form, it is a quick way of setting up a scene that can be refined by other graphics tools.
For software development, many visual tools allow programmers to generate applications by drawing lines between predefined modules. But a combination of graphics and controlled NL can be used to design, specify, and implement every aspect of a system at any level of detail. Petri nets are one of the most general graphics tools, and they have been used successfully to design and implement complex network applications with distributed interactions among multiple agents. Yet every link and node of a Petri net can be specified in the Horn-clause subset of FOL, and every Horn-clause can be written as an if-then sentence in controlled English, as illustrated in Section 2. A combination of Petri nets with controlled NLs can provide a complete programming language. Programmers should have the option of using conventional programming languages, but they could also create or modify modules by graphic manipulation or by statements in a controlled NL, and the system could respond by explaining any node or link by a comment in the same NL. Any declarations or details that cannot be shown graphically can be stated in a controlled NL.
Under the name of activity diagrams, Petri nets are one of the diagrams used in the Unified Modeling Language. The UML diagrams specify information at one of four metalevels: the metametalanguage defines the syntax and semantics of the UML diagrams; the metalanguage defines the general-purpose UML types; a systems analyst defines application types as instances of the UML types; finally, the working data of an application program consists of instances of the application types. To provide a unified view of all these levels, Gerbé and his colleagues (1998) implemented design tools that use conceptual graphs as the representation language at every level. For his PhD dissertation, Gerbé (2000) developed an ontology for using CGs as the metametalanguage for defining CGs themselves. He also applied it to other notations, including the UML diagrams and the Common KADS system for designing expert systems. Using that theory, Gerbé and his colleagues developed the Method Repository System as an authoring environment for editing, storing, and displaying descriptions of business rules and processes. Internally, the knowledge base is stored in conceptual graphs, but externally, the graphs can be translated to web pages in either English or French. About 200 business processes were modeled in a total of 80,000 CGs.
Widespread acceptance of any new language or interface occurs when the total effort for application design, development, and deployment is significantly reduced in comparison to more familiar methods. Over the past thirty years, many natural-language query systems (which could more accurately be called controlled NL systems) were developed, and they were generally much easier to use than SQL. The major stumbling block that has prevented them from becoming commercially successful is the amount of effort required to define the vocabulary terms and map them to the appropriate database fields. If that effort is added on top of the application design and development, acceptance will be slow. If it requires trained linguists or even people who remember their high-school grammar lessons, acceptance will be nearly impossible.
For controlled NLs to be successful, the tools for building applications based on them must be easy to use by current software developers, and they must accommodate legacy applications based on older technologies. One way to achieve that goal is to give the developers an interface that is as easy to use as the ones they design for their own users. Such an interface should be supported by the following kinds of tools and resources:
Completely new tools can be introduced for purposes that have not been handled adequately by older tools. An important example is the task of analyzing, editing, and translating documentation to a computable form. Skuce and his colleagues (2000) designed tools that help an editor select, analyze, and translate unrestricted natural language to a controlled NL called ClearTalk. The knowledge editing (KE) tools for writing controlled NLs have the following advantages over specialized notations for defining ontologies, rules, and other knowledge representations:
Even IT professionals need help in dealing with the proliferation of new languages and notations for every aspect of their jobs. The tools that are supposed to help them often add to their burden, as one systems programmer expressed in a poignant cry:
Any one of those development tools, by itself, can be a tremendous aid to productivity, but any two of them together can kill you.No one should be required to learn different languages for the database, the ontologies, the web pages, the programming, the servers, the clients, the network, and the open-ended variety of "helpful" development tools. Everything can be done with the syntax and vocabulary of the user's native language, supplemented with appropriate graphics for each aspect of the process. Any expert who prefers to use a more specialized language for some aspect of software development is welcome to use it, but nobody can be an expert in every aspect simultaneously.
By itself, a controlled NL solves only the syntactic part of the problem, which is not the most difficult aspect of learning any programming system. Even harder is learning the names, icons, or menu locations that somebody chose for every feature. What one person calls a directory, another will call a folder. One person says "import", and another says "include"; "bookmarks" or "favorites"; "branch" or "jump"; "network" or "graph"; "call", "perform", "execute", or "do"; "subroutine", "procedure", "function", or "method". Sometimes these terms are synonyms, sometimes they mark important distinctions, and sometimes different people distinguish them differently. Standardized terminologies are useful, but new terms are constantly being invented, old terms become obsolete, and the total number of terms grows beyond anyone's capacity to learn, remember. or use. The semantic structures and behaviors associated with those terms are still harder to learn. Finally, the hardest to learn and most important of all is knowing how to use these things and why. The fundamental issues are semantics and pragmatics.
Th techniques for finding and using the correct semantic structures, which are essential for understanding unrestricted NLs, can also be used to assist users who stray outside the boundaries of a controlled NL. As an example, Sowa and Majumdar (2003) showed how the Intellitex parser and the VivoMind Analogy Engine (VAE) were able to retrieve semantic structures and use them during the process of language interpretation. In one major application, LeClerc and Majumdar (2002) used Intellitex and VAE to analyze both the programs and the documentation of a large corporation, which had systems in daily use that were up to forty years old. Although the documentation specified how the programs were supposed to work, nobody knew what errors, discrepancies, and obsolete business procedures might be buried in the code.
The task, called legacy re-engineering, required an analysis of 100 megabytes of English, 1.5 million lines of COBOL programs, and several hundred control-language scripts, which called the programs and specified the data files and formats. Over time, the English terminology, computer formats, and file names had changed. Some of the format changes were caused by new computer systems and business practices, and others were required by different versions of federal regulations. The requirements were to analyze any English text or programming code that referred to files, data, or processes in any of the three languages (English, COBOL, and JCL), to generate an English glossary of all process and data terminology, to define the specifications for a data dictionary, to create UML diagrams of all processes and data structures, and to detect inconsistencies between the documentation and the implementation.
To understand the power and limitations of the Intellitex parser and semantic interpreter, it is important to realize that Intellitex cannot, by itself, translate informal English to executable programs. That possibility was dismissed by the pioneer in computer science Alan Perlis, who observed "It is not possible to translate informal specifications to formal specifications by any formal algorithm." English syntax is not what makes the translation difficult. The difficulty arises from the enormous amount of background knowledge that lies behind every word in English or any other natural language.
But Intellitex was not used to translate informal English to formal conceptual graphs. Instead, Majumdar first used it to analyze the formal specifications written in COBOL, JCL (Job Control Language), and the database specifications. Those unambiguous specifications, which were translated to conceptual graphs, became the semantic structures that were then used to interpret the English documentation. When Intellitex processed English sentences, it used the previously generated CGs to resolve ambiguities and to provide the necessary background knowledge. As an example, the following paragraph is taken from the documentation:
The input file that is used to create this piece of the Billing Interface for the General Ledger is an extract from the 61 byte file that is created by the COBOL program BILLCRUA in the Billing History production run. This file is used instead of the history file for time efficiency. This file contains the billing transaction codes (types of records) that are to be interfaced to General Ledger for the given month. For this process the following transaction codes are used: 32 — loss on unbilled, 72 — gain on uncollected, and 85 — loss on uncollected. Any of these records that are actually taxes are bypassed. Only client types 01 — Mar, 05 — Internal Non/Billable, 06 — Internal Billable, and 08 — BAS are selected. This is determined by a GETBDATA call to the client file. The unit that the gain or loss is assigned to is supplied at the time of its creation in EBT.Most of the words in this paragraph are found in the VivoMind dictionary, which is based on WordNet with numerous additions and extensions. Many other words, however, are not found, such as BILLCRUA, GETBDATA, and EBT. In isolation, this paragraph would be difficult for a human to understand. However, this paragraph did not appear in isolation. The background knowledge necessary to interpret most of the unknown words was found by first processing the COBOL and JCL programs. The names, types, and interrelationships of all the files, programs, data structures, and variables were found in those programs. As Intellitex processed the COBOL and JCL programs, it added those names to its dictionary along with their types and the CGs that represented their relationships to other data. When it processed English, Intellitex used that information to resolve ambiguities and to relate information from different sources. This task is sometimes called knowledge fusion.
This example also illustrates how Intellitex can process a wide range of syntactic constructions with a rather simple grammar. A phrase such as "32 — loss on unbilled" is not covered by any published grammar of English. When Intellitex found that pattern, it did not reject it; instead, it translated it to a rudimentary conceptual graph that linked the concept [Number: 32] by an unknown relation to a CG of the following form:
[Loss]→(On)→[Unbilled]The result was stored as a tentative interpretation with a low weight of evidence. But Intellitex soon found two more phrases with the same syntactic pattern: "72 — gain on uncollected" and "85 — loss on uncollected". Therefore, Intellitex assumed a new grammar rule for this pattern, gave a name to the unknown relation, and associated it with the new grammar. By using VAE to find analogies to the CGs found in the COBOL programs, Intellitex discovered the particular COBOL program that defined the unknown relation, and it verified that 32, 72, and 85 were transaction codes assigned to subprocedures in that program. Although that syntactic pattern is not common in the full English language, it is important for the analysis of at least this one document. Such patterns, which may be called nonce grammar, often occur in specialized sublanguages of technical English, as used in business, law, medicine, science, engineering, and the military.
In three weeks of computation on a 750 MHz Pentium III, VAE combined with the Intellitex parser was able to analyze all the documentation and programs and generate one CD-ROM containing the required results. Several factors enabled Intellitex to process unrestricted English:
The method of using VAE to find the semantic structures needed for interpreting natural language can also support a powerful help facility for correcting sentences that fall outside the boundaries of a controlled NL. By supplementing a controlled NL parser with Intellitex and VAE, the KE tools could support a two-level system:
Austin, John L. (1962), How to do Things with Words, second edition edited by J. O. Urmson & Marina Sbisá, Harvard University Press, Cambrige, MA, 1975.
Coyne, Bob, & Richard Sproat (2001) "WordsEye: An automatic text-to-scene conversion system," Proc. SIGGRAPH 2001, Los Angeles.
Cyre, W. R., S. Balachandar, & A. Thakar (1994) "Knowledge visualization from conceptual structures," in Tepfenhart et al. (1994) Conceptual Structures: Current Practice, Lecture Notes in AI 835, Springer-Verlag, Berlin, pp. 275-292.
Cyre, W. R. (1997) "Capture, integration, and analysis of digital system requirements with conceptual graphs," IEEE Trans. Knowledge and Data Engineering, 9:1, 8-23.
Cyre, W. R., & P. Victor (2001) "An intelligent interface for model documentation with controlled english," Proc. IASTED 2001, Pittsburgh.
Fuchs, Norbert E., Uta Schwertel, Rolf Schwitter (1999) Attempto Controlled English (ACE), Language Manual, Technical Report ifi-99.03, University of Zurich. For further detail, see http://www.ifi.unizh.ch/attempto/
Gerbé, Olivier, R. Keller, & G. Mineau (1998) "Conceptual graphs for representing business processes in corporate memories," in M-L Mugnier & Michel Chein, eds., Conceptual Structures: Theory, Tools, and Applications, LNAI 1453, Springer-Verlag, Berlin, pp. 401-415.
Gerbé, Olivier (2000) Un Modèle uniforme pour la Modélisation et la Métamodélisation d'une Mémoire d'Entreprise, PhD Dissertation, Département d'informatique et de recherche opérationelle, Université de Montréal.
Halliday, M.A.K. and R. Hasan (1976) Cohesion in English, Longman, London.
Harris, Roy (1988) Language, Saussure, and Wittgenstein: How to Play Games with Words, Routledge, London.
Mann, William C., & Sandra A. Thompson (1987) "Relational Propositions in Discourse," Discourse Processes 9:1, pp. 57-90.
Martin, Philippe (2002) "Knowledge representation in CGLF, CGIF, KIF, Frame-CG and Formalized-English,"
Martin, Philippe (2003) "Translations between UML, OWL, KIF, and the WebKB-2 languages (For-Taxonomy, Frame-CG, Formalized English)," http://meganesia.int.gu.edu.au/~phmartin/WebKB/doc/model/comparisons.html
McCarthy, John (1989) "Elephant 2000: A programming language based on speech acts," http://www-formal.stanford.edu/jmc/elephant.html
Nubiola, Jaime (1996) "Scholarship on the relations between Ludwig Wittgenstein and Charles S. Peirce," in I. Angelelli & M. Cerezo, eds., Proceedings of the III Symposium on the History of Logic, Gruyter, Berlin.
Peter of Spain or Petrus Hispanus (circa 1239) Summulae Logicales, edited by I. M. Bochenski, Marietti, Turin, 1947.
Schwitter, Rolf (1998) Kontrolliertes Englisch fúr Anforderungsspezifikationen, Studentdruckerei, Zurich. For further references, see http://www.ics.mq.edu.au/~rolfs/controlled-natural-languages/
Skuce, Doug (2000) "Integrating web-based documents, shared knowledge bases, and information retrieval for user help," Computational Intelligence 16:1.
Sowa, John F. (2000) Knowledge Representation: Logical, Philosophical, and Computational Foundations, Brooks/Cole, Pacific Grove, CA.
Sowa, John F. (2002) "Architectures for Intelligent Systems," IBM Systems Journal 41:3, pp. 331-349.
Sowa, John F. (2003) "Laws, facts, and contexts: Foundations for multimodal reasoning," in V. F. Hendricks et al., eds., Knowledge Contributors, Kluwer, Dordrecht, pp. 145-184.
Sowa, John F., & Arun K. Majumdar (2003) "Analogical reasoning," in A. de Moor, W. Lex, & B. Ganter, eds., Conceptual Structures for Knowledge Creation and Communication, LNAI 2746, Springer-Verlag, Berlin, pp. 16-36.
Sowa, John F. (2004) "Common Logic Controlled English Specifications," http://www.jfsowa.com/clce/specs.htm
Wittgenstein, Ludwig (1953) Philosophical Investigations, Basil Blackwell, Oxford.